Beyond OCR: Benchmarking Question-Answering on Complex Industrial PDFs with TIA-pdf-QA-Bench

Introduction
A growing number of benchmark datasets have emerged for evaluating document understanding, particularly in areas like Optical Character Recognition (OCR), information extraction, and question answering (QA). However, many existing benchmarks rely on clean document formats or fail to evaluate end-to-end QA pipeline quality. This makes them insufficient for assessing real-world industrial documents where noise, formatting variability, and complex semantics are the norm.
At ThirdAI Automation, we address a fundamental question: How well can we answer questions based on complex, semi-structured PDF documents from industrial domains? To solve this, we created TIA-pdf-QA-Bench, a new benchmark evaluating end-to-end QA performance over PDFs with emphasis on retrieval-augmented generation (RAG) pipelines.
Why Traditional OCR Benchmarks Fall Short
OCR performance is traditionally evaluated in isolation using word/character accuracy metrics. While useful for assessing text extraction fidelity, this approach misses a crucial downstream impact: How do OCR mistakes affect real use cases like question answering?
For example:
- A single misrecognized term in a spec sheet might negligibly impact OCR scores
- The same error could derail a QA system extracting critical parameters
- We don't just care if text is readable—we care if it's useful for the task
The Real Challenge: Retrieval and Understanding
OCR is just the beginning. Extracted text must be chunked, linked, and indexed to enable effective retrieval and reasoning. Industrial documents present unique challenges:
- Long documents with heterogeneous formatting
- Tables, figures, and side-by-side layouts
- Implicit references and domain-specific terminology
- Dense hierarchical structures (specifications, standards)
In TIA-pdf-QA-Bench, we found that text chunking and representation structure profoundly impacts QA performance. Poor chunking leads to:
- Missed answers
- Irrelevant retrievals
- Hallucinations in generative models
About TIA-pdf-QA-Bench
TIA-pdf-QA-Bench evaluates QA quality on real-world industrial documents with these features:
- Uses authentic PDFs from industrial partners and public sources
- Simulates realistic QA scenarios (domain terminology, multi-hop reasoning)
- Evaluates end-to-end pipeline (OCR → preprocessing → retrieval → answer generation)
We tested multiple RAG pipelines using:
- OCR tools: Tesseract, Azure OCR
- Chunking strategies: Fixed-length vs. semantic
- Retrieval methods: Dense vs. sparse
Key Insights
ThirdAI Automation's RAG framework achieved the highest QA accuracy in our benchmark:
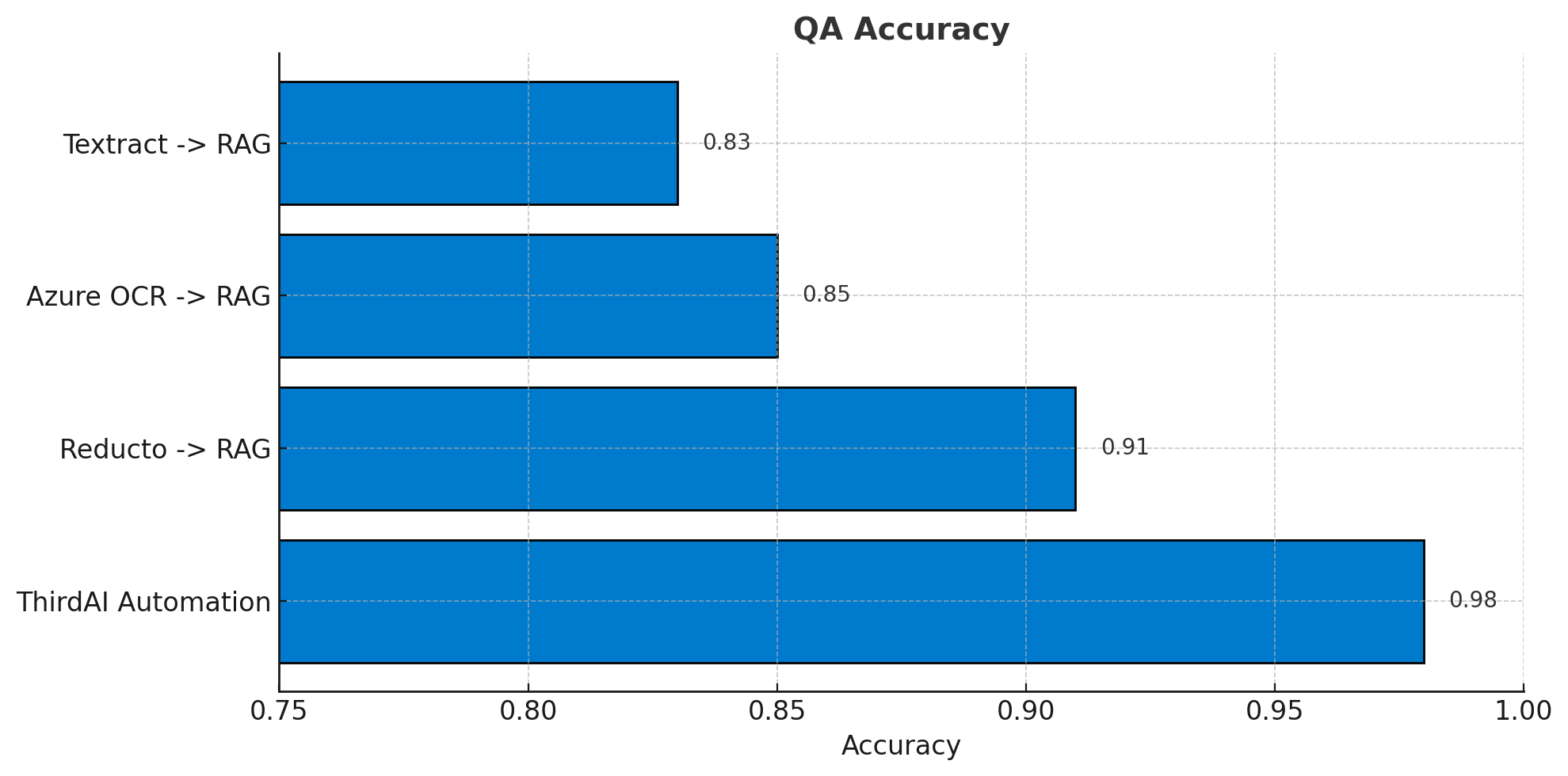 ThirdAI's RAG framework outperformed alternatives in industrial document QA
ThirdAI's RAG framework outperformed alternatives in industrial document QA
More benchmark details will be released in an upcoming research paper!
What's Next?
TIA-pdf-QA-Bench advances realistic, task-oriented evaluation of document intelligence systems. We're expanding the benchmark with:
- More document types
- Richer annotations
- Harder questions to identify failure cases
Example document from our benchmark:
 Complex industrial documents in our benchmark require advanced understanding capabilities
Complex industrial documents in our benchmark require advanced understanding capabilities
Grow With Us
Working on industrial document QA or building PDF reasoning systems? Reach out to our team
We're releasing an API for testing our OCR, Chunking and RAG functionalities! Join the waitlist for early access.